|
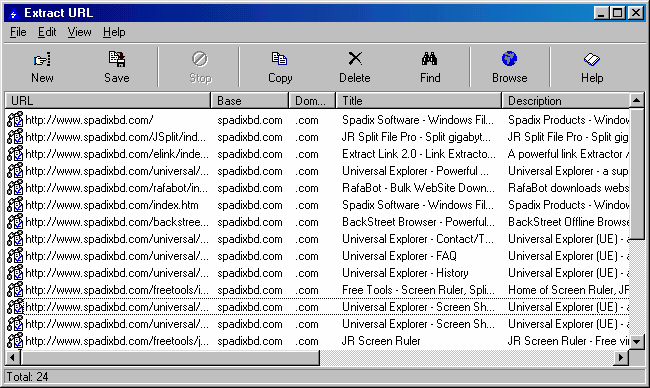
Extract URL with
title, description, keywords meta data from entire websites, list
of URLs or search engine results.
It presents results in url, base, domain, title, description,
keyword, date modified, page size, etc. and user can save
extracted data in text, excel, html file or CSV text format to
import the output in any complex database tool as desire.
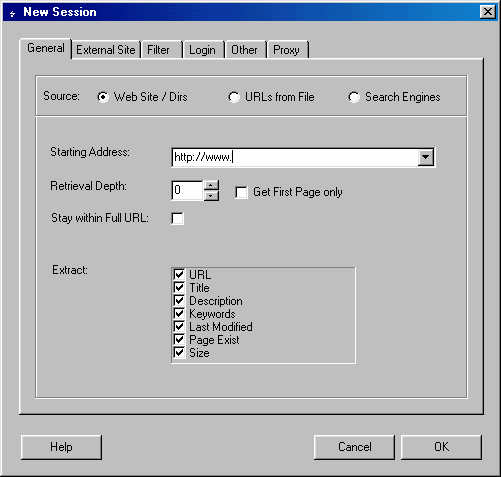
Program has numerous filters to restrict extraction like - URL
filter, date modified, file size, etc. It allows user-selectable
recursion levels, retrieval threads, timeout, proxy support and
accesses password-protected sites.
v1.6 (Released 10.08.2015):
Screen
Shots
FAQ
Q:
What is the maximum links quantity the Extract URL can
process?
A:
The limit is 32,000 URLs/pages per session. If you need to
extract more pages per session, then try Win
Web Crawler - it saves extracted data directly to disk
file, so there is no limit.
|
Q:
I set up following custom engine source:
http://search.ke.voila.fr/S/voila?kw={SEARCH_KEYWORD}&lg=fr&bl=fr&gb=site&cid=ng&ap=16&dd=web&an=50
It works ok, but
when I change last 50 to 100 to get more URLs, it doesn't
work.
A:
This is not problem of "Extract URL", rather
the search engine doesn't support sending more than 50
results at a time. We suggest you to make many instances
to search from page 1 to 50 and then from 50 to 100 so on
.. using correct string. The more search engine sources
you add, the more results you get.
|
Q:
When I aim "Extract URL" at http://dmoz.org/Kids_and_Teens/Computers/Internet/ I would expect to see all links
listed there with descriptions. How come?
A: After
entering http://dmoz.org/Kids_and_Teens/Computers/Internet/ in starting address box, move to
"External Site" tab and check "Follow
External URLs" option. This option tells program to
visit all linked site and extract titile and other info.
|
System
Requirements: Windows 95/98/2000/NT/ME/XP/7/8, 32 MB RAM, 1
MB Hard Disk Space, Internet Connection.
|
